Ich experimentiere mit Text-to-Speech-Softwares, die das Problem der Quantität und potentiellen, qualitativen Heterogenität bei der Erzeugung von Sprachpassagen mit einem Schlag lösen könnten.
Mesosticha TtS Generierung (Stimmnamen: m Reiner, f Klara)
Erstes Substantiv (Geschlecht m/f) definiert Lesestimme

(Screenshot: Online-TtS-Software http://www2.research.att.com/~ttsweb/tts/demo.php)
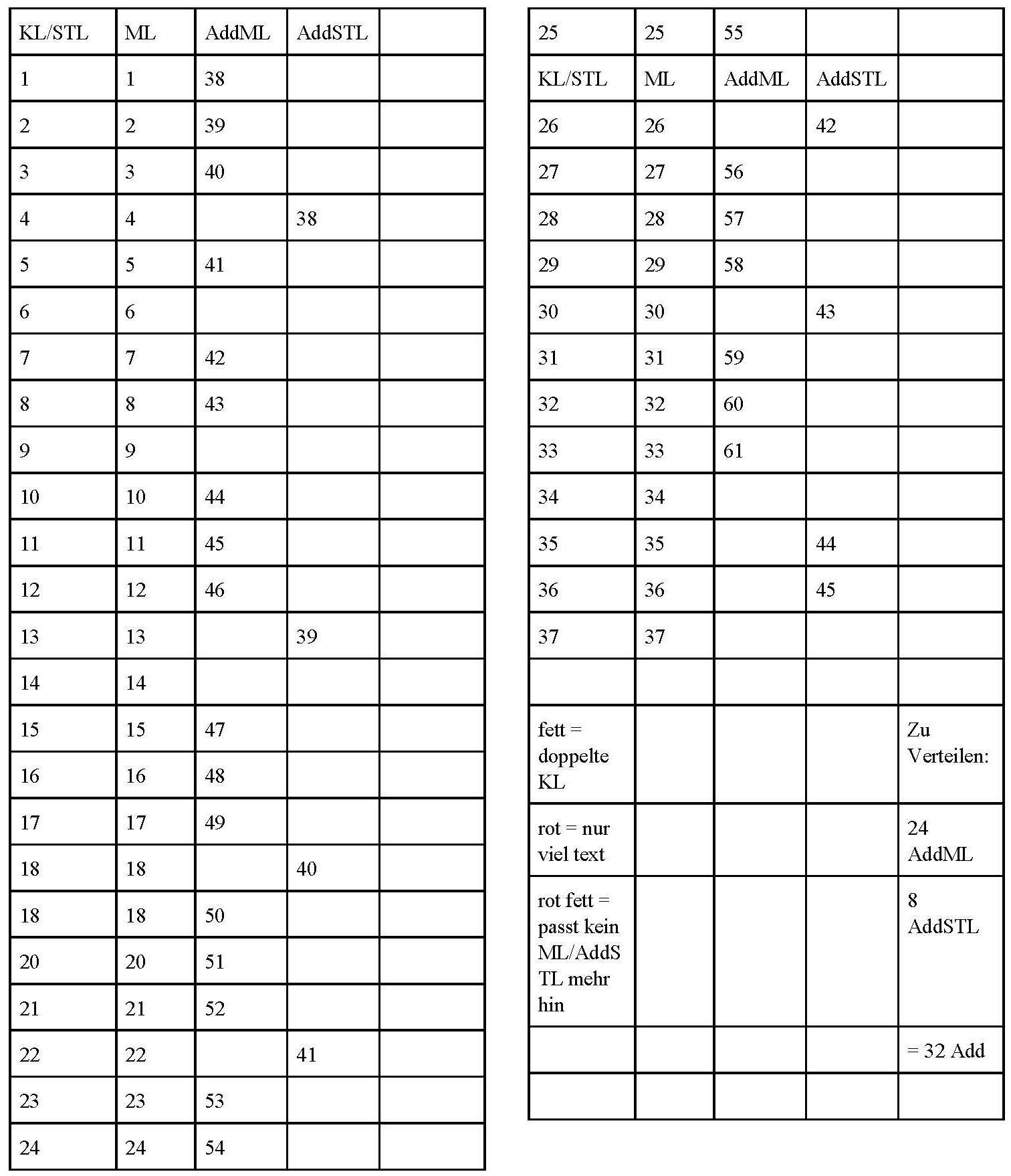
61 Soundfiles (Names ff.: M01_tts_Male.wav) sind auf ein zweites Soundboard mit 2 Racks zu platzieren. Weitere Beobachtungen:
-> Vor allem Überschneidung (overlap) mehrerer Files hören sich gut an und machen das Stück lebendig.
-> Zu überlegen, ob nicht vielleicht auch die STL-Texte im TtS-Verfaren als Files (45) zu generieren wären
Das gesamte Arrangement würde allerdings komplett den Charakter einer Lesung einbüssen, stattdessen erhälte es evtl. den Charakter einer DJ-Session.
Folgende (kostenlose) Softwares sind ebenfalls zu testen:
http://codewelt.com/proj/speak (2/5)
http://www.fromtexttospeech.com/ (4/5)
Stimmen: m/f, Sarah/Klaus, Satzzeichen sind zu entfernen, da sonst (unverständlich) mitgesprochen -> Weitere Anforderungen: Zeilenumbrüche einfügen
kürzere Sätze
alle Umlaute müssen ausgeschrieben werden zu ü zu ue etc
)
mehr: http://myappmag.com/free-online-text-to-speech-voice-converter/
Auch denkbar wäre der gesamte Sprechtext der STL in einem sauber angepassten File, das entsprechend nach Ablauf einer STL-Passage angehalten wird
(Elemente mit Titel?: Zahl Ort (Start) -> Ende Zahl Ort (Ende) (1) ) (= verworfen. Aber: Zu überprüfen wäre, ob solch ein Gesamt-File nicht mit einer speziellen Software nach Passagen getrackt werden könnt. Zu testen, bspw., die Software Slice Audio File Splitter.)
Eine zweite Text-to-Speech-Software soll also die Stimme für die Passagen der STL generieren.
(Screenshot: http://www.fromtexttospeech.com/)
Das Ergebnis liegt in einer Datei. Zur Abspielung benötigt wird noch etwas Hardware:
Ich lege das File in ein Android Tablet und installiere eine extragrosse PLAY/PAUSE-Taste.

(Screenshot: PLAY/PAUSE-Taste auf Android Tablet)
Wie vermutet ist eine Bedienung nach diesem Verfahren in einer multitaskerischen Performance zu umständlich, sodass diese Idee verworfen werden muss. Und weitergearbeitet werden muss mit dem Versuch, aus den STL-Passagen Einzelfiles für ein weiteres Soundboard zu erzeugen.
Derweil wird Arbeitstitel und Untertitel dieser Arbeit revidiert:
Recycling Le Tour de France
Komposition für drei Soundboards, eine Yamaha PSR-420 und diverse, künstliche Stimmen
————
1 Diese Idee wird nach Praxistest verworfen. Das Verfahren ist live nicht gut handlebar